The
World Wide Web
(
WWW
, or simply
Web
) is an information space in which the items of interest, referred to as resources, are identified by global
identifiers called Uniform Resource Identifiers (URI).
The Web makes use of a single global identification system: the URI. URIs are a cornerstone of Web
architecture, providing identification that is common across the Web.
By design a URI identifies one resource. We do not limit the scope of what might be a resource. The term
"resource" is used in a general sense for whatever might be identified by a URI. It is conventional on the
hypertext Web to describe Web pages, images, product catalogs, etc. as “resources”. The distinguishing
characteristic of these resources is that all of their essential characteristics can be conveyed in a
message. We identify this set as “information resources.”
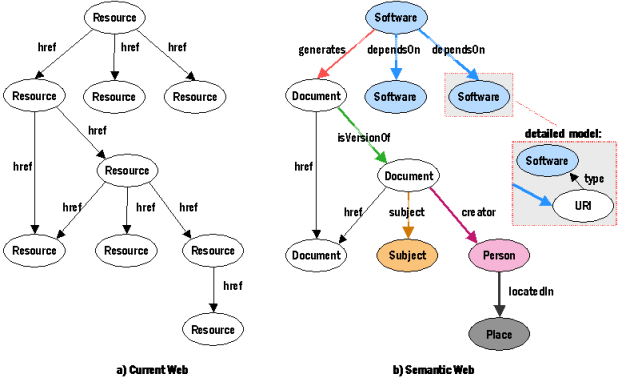
The web —a complex system of interconnected components which has become a global repository of vast
distributed heterogeneous data and services. The web has metamorphosed through generations from web 1.0
—which allows for published contents to be searched and read (read only), through web 2.0 — which allows for
dynamism and collaborations (read and write) to web 3.0 — which extends collaboration by allowing machine
participation (read, write, and execute). Web 3.0, also referred to as the semantic web, became incumbent as
a result of the need to efficiently and effectively exploit the massive information and services on the web.
Back in 1989, at CERN (the scientific research laboratory near Geneva, Switzerland), Tim Berners-Lee
presented a proposal for an information management system that would enable the sharing of knowledge and
resources over a computer network. We now know this system as the worldwide web (the web).
(Shklar & Rosen 2012, p. 1.1)
Web 3.0
Web 2.0 is a harking back to the web as a network for presenting personal hyperlinked information.
Information flow on the web is no longer one way, from the web site to the surfer.
In 2006, the concept of Web 3.0 was introduced during the Technet Summit. Jerry Yang, the founder of Yahoo,
acknowledged the hardware and software challenges associated with Web 2.0 and proposed the need for a new,
truly inclusive web platform. He believed that the power of the web had reached a critical point and called
for a web vehicle that would bridge the gap between professional, and semi-professional users, and
consumers, encouraging collaborative web interactions and network effects. This new generation of web
business and applications became known as Web 3.0.
Since then, influential figures in the internet community, including Google CEO Eric Schmidt and Nifty
founder Reed Hastings, have contributed to the discourse surrounding Web 3.0. Tech entrepreneur and investor
Chris Dixon has described Web 3.0 as an internet for both builders and users, where digital assets play a
crucial role in connecting them.
However, there is no universally accepted definition of Web 3.0.Web 3.0 represents the tangible
manifestation of current technology trends moving towards a new level of maturity. These trends include the
internet, network computing, open technologies, open identities, intelligent networks, distributed
databases, intelligent applications, and more.
(Cheng 2024, 17-18)
History of the World Wide Web
Way back during Christmas 1990, Sir Tim Berners-Lee and his team at CERN built all the tools necessary for a
working web. They created HTTP, HTML, and the world's first web browser, called WorldWideWeb. The web pages
that the first browser could run were simple plain-text pages with hyperlinks. In fact, those first web
pages are still online and available to view today.
(Hume & Osmani 2018, p. 27)
Semantic Web
Semantic Web technologies are a set of standards and protocols aimed at enhancing the meaning and
understanding of data on the World Wide Web. Unlike traditional web technologies that primarily focus on the
presentation of information, Semantic Web technologies aim to enable machines to comprehend the semantics or
meaning of data, facilitating more intelligent data processing and interaction. At its core, the Semantic
Web is based on the principles of annotating data with metadata that describe its meaning and relationships
in a machine-readable format. This metadata enables automated reasoning, inference, and integration of
disparate data sources, thereby enabling more sophisticated applications and services.
In addition to the classic “Web of documents” and the ontologies, the paradigm of publication, linking, and
consumption of data has evolved to support a “Web of data”, whose main goal is generating a global Linked
Data ecosystem known as Linked Open Data cloud (LOD cloud), which enables the computers to do more useful
work and to develop systems that can support trusted interactions over the network. In this sense, the Web
of data enables developing vertical applications that may bring forward specific and sometimes highly
non-trivial use cases, focusing to provide solutions to problems of different industries, such as Health
Care and Life Sciences, eGovernment, and Energy, to mention but a few, in order to improve collaboration,
research and development, and innovation adoption through Semantic Web technology.
(Alor-Hernández 2019, p. v)
HTML
HTML
HTML IS THE unifying language of the World Wide Web. Using just the simple tags it contains, the human race
has created an astoundingly diverse network of hyperlinked documents. HTML5 is the latest iteration of this
lingua franca. While it is the most ambitious change to our common tongue, this isn't the first time that
HTML has been updated. The language has been evolving from the start.
As with the web itself, the HyperText Markup Language was the brainchild of Sir Tim Berners-Lee. In 1991, he
wrote a document called “HTML Tags” in which he proposed fewer than two dozen elements that could be used
for writing web pages.
Sir Tim didn't come up with the idea of using tags consisting of words between angle brackets; those kinds
of tags already existed in the SGML (Standard Generalized Markup Language) format. Rather than inventing a
new standard, Sir Tim saw the benefit of building on top of what already existed—a trend that can still be
seen in the development of HTML5.
(Keith 2016, 5-6)
Progressive Web Applications
Progressive Web Applications (PWAs)
A Progressive Web App (PWA) is a web app that leverages special browser capabilities that enable the app to
act more like a native or mobile app when running on capable browsers. That's it, that's all that needs to
be said.
What is a 'web application?' It is a client-server application that uses a web browser as its client
program.
(Shklar & Rosen 2012, p. 1.3)
Major browser vendors have been working together to improve the way we build for the web and have created a
new set of features that give web developers the ability to create fast, reliable, and engaging websites. A
PWA should be all of these things:
Responsive
Connectivity-independent
Interactive with a feel like a native app's
Always up-to-date
Safe
Discoverable
Re-engageable
Installable
Linkable
(Hume & Osmani 2018, pp. 34-35)
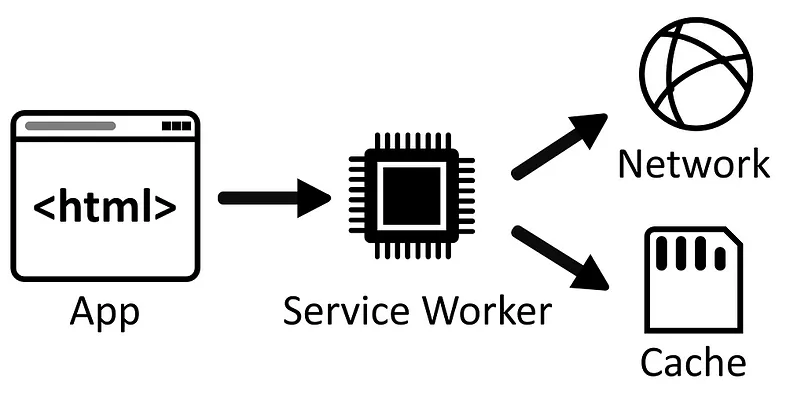
PWAs point to a file known as a manifest file that contains information about the website, including its
icons, background screen, colors, and default orientation. […] A PWA should also be able to work offline.
Using Service Workers, you can selectively cache parts of your site to provide an offline experience.
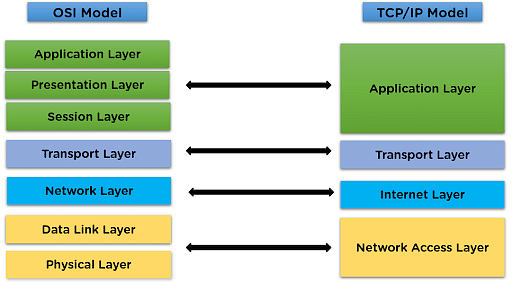
OSI Network Architecture 7 Layers Model Open Systems Interconnection (OSI) model is a reference model
developed by ISO (International Organization for Standardization) in 1984, as a conceptual framework of
standards for communication in the network across different equipment and applications by different vendors.
It is now considered the primary architectural model for inter-computing and internetworking communications.
Most of the network communication protocols used today have a structure based on the OSI model.
(Network Protocols Handbook 2007)
The TCP/IP Protocol Suite
TCP/IP, the protocol on which the Internet is built, is not a single protocol but rather an entire suite of
related protocols. TCP is even older than Ethernet. It was first conceived in 1969 by the Department of
Defense. For more on the history of TCP/IP, see the sidebar, “The fascinating story of TCP/IP,” later in
this chapter. Currently, the Internet Engineering Task Force (IETF) manages the TCP/IP protocol suite.
The TCP/IP suite is based on a four-layer model of networking similar to the seven-layer OSI model. Figure
1-7 shows how the TCP/IP model matches up with the OSI model and where some of the key TCP/IP protocols fit
into the model. As you can see, the lowest layer of the model, the network interface layer, corresponds to
the OSI model's physical and data link layers. TCP/IP can run over a wide variety of network interface layer
protocols, including Ethernet, as well as other protocols, such as token ring and FDDI (an older standard
for fiber-optic networks). The application layer of the TCP/IP model corresponds to the upper three layers
of the OSI model — the session, presentation, and application layers. Many protocols can be used at this
level. A few of the most popular are HTTP, FTP, Telnet, SMTP, DNS, and SNMP.
TCP (Transmission Control Protocol), is a reliable connection-oriented protocol that allows a byte stream
originating on one machine to be delivered without error on any other machine in the internet. It segments
the incoming byte stream into discrete messages and passes each one on to the internet layer. At the
destination, the receiving TCP process reassembles the received messages into the output stream.
The Application Layer
On top of the transport layer is the application layer. It contains all the higher- level protocols. The
early ones included virtual terminal (TELNET), file transfer (FTP), and electronic mail (SMTP). Many other
protocols have been added to these over the years. Some important ones that we will study, shown in Fig.
1-34, include the Domain Name System (DNS), for mapping host names onto their network addresses, HTTP, the
protocol for fetching pages on the World Wide Web, and RTP, the protocol for delivering real-time media such
as voice or movies.
(Tanenbaum, Feamster & Wetherall 2021)
TCP/IP Clients and Ports
Web applications are a prime example of thin clients. Rather than building a custom program to perform
desired application tasks, web applications use the web browser, a program that is already installed on most
end-user systems. You cannot create a client much thinner than a program that users already have on their
desktops!
How Do TCP/IP Clients and Servers Communicate with Each Other?
TCP/IP client programs open a socket, which is simply a TCP connection between the client machine and the
server machine. Servers listen for connection requests that come in through specific ports.
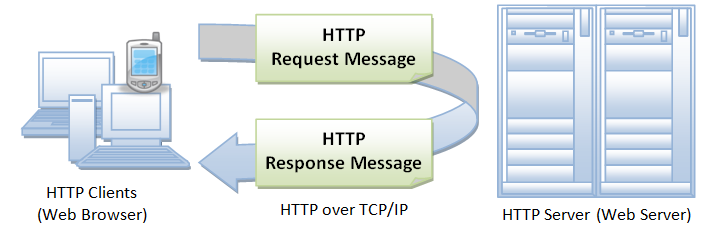
Understanding HTTP is critical to the design of advanced web applications. It is a prerequisite for
utilizing the full power of Internet technologies […] Knowledge of the inner workings of HTTP promotes
reasoning from first principles, and simplifies the daunting task of learning the rich variety of protocols
and APIs that depend on its features […] Each HTTP exchange consists of a single request and a single
response.
Persistent Connections
Since HTTP is a stateless protocol, it does not require persistent connections. A connection is supposed to
last long enough for a browser to submit a request and receive a response.
Structure of HTTP messages
HTTP messages (both requests and responses) have a structure similar to e-mail messages; that is, they
consist of a block of lines comprising the message headers, followed by a blank line, followed by a message
body. However, HTTP messages are not designed for human consumption and have to be expressive enough to
control HTTP servers, browsers, and proxies.
Request Methods
There are a variety of request methods specified in the HTTP protocol. The most basic ones defined in
HTTP/1.1 are GET, HEAD, and POST. In addition, there are the less commonly used PUT, DELETE, TRACE, OPTIONS,
and CONNECT.
GET method
GET is the simplest of the request methods. When you type a URL in your browser, follow a bookmark, or click
on a hyperlink to visit another page, the browser uses the GET method when making the request to the web
server.
Processing HTTP Requests
The act of sending an HTTP request to a web server consists of three basic steps: constructing the HTTP
request (Request Generation module), establishing a connection (Networking module) across the Internet to
the target server or an intermediate proxy, and transmitting the request (Networking module) over the
established connection.
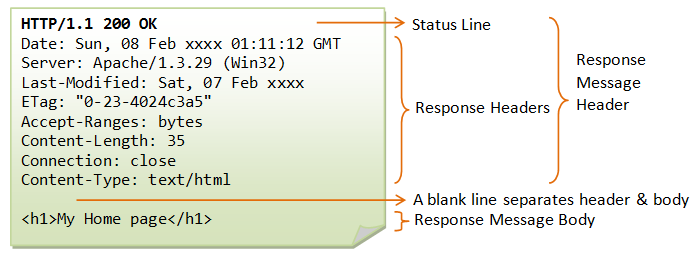
Processing HTTP Responses
An HTTP response message consists of a status line (containing the HTTP version, a three-digit status code,
and a brief human-readable explanation of the status code), a series of headers (one per line), a blank
line, and finally the body of the response.
In the dynamic landscape of modern web development, APIs (Application Programming Interfaces) play a pivotal
role, enabling seamless communication between different software components and services. […] As the
backbone of modern web applications, APIs are essential for connecting diverse systems, enabling developers
to harness the power of third-party services, and fostering interoperability. […] REST (Representational
State Transfer) is a fundamental architectural style that underpins many of the APIs that we interact with
daily. The client-server model is at the heart of REST, defining clear roles and responsibilities for both
clients and servers. APIs also encourage modularity, reusability, and collaboration among development teams.
Rather than building everything from scratch, developers can focus on their core competencies and utilize
APIs to handle specialized tasks such as payment processing, authentication, geolocation, and more.
GraphQL: A Paradigm Shift in API Querying. GraphQL is a query language and runtime for APIs that enables
clients to precisely request the data they need, reducing over-fetching and minimizing round-trips to the
server. Its key advantages include: Efficiency: Clients control the data they receive, eliminating
unnecessary data transfers. Flexibility: A single GraphQL endpoint allows for complex queries and mutations.
Strong typing: A schema defines the available types and operations, leading to clear and validated
documentation.
Responsive Web Design (RWD) is a strategy for providing appropriate layouts to devices based on the size of
the viewport (browser window). The key to Responsive Web Design is serving a single HTML document (with one
URL) to all devices, but applying different style sheets based on the screen size in order to provide the
most optimized layout for that device.
(Niederst Robbins 2018, 40)
In 2010, Ethan Marcotte gave name to another, more flexible solution in his article “Responsive Web Design”
(alistapart.com/article/responsive-webdesign), which has since become a cornerstone of modern web design. In
this chapter, I will follow the “ingredients” for RWD that Ethan outlines in his book Responsive Web Design
(A Book Apart).
The technique has three core components:
A flexible grid Rather than remaining at a static width, responsive sites use methods that allow them to
squeeze and flow into the available browser space.
Flexible images Images and other embedded media need to be able to scale to fit their containing elements.
CSS media queries Media queries give us a way to deliver sets of rules only to devices that meet certain
criteria, such as width and orientation.
To this list of ingredients, I would add the viewport meta element, which makes the width of the web page
match the width of the screen. That's where we'll begin our tour of the mechanics of RWD.
(Niederst Robbins 2018, 487)
We can make the page more mobile friendly by adding this snippet in the
<head>
:
This viewport meta tag is the non-standard but de facto way of telling the browser how to render the page.
Although introduced to the web by Apple, rather than a standard process, it remains essential for responsive
web design.
(Frain 2022, 12)
Version Control
Git
Git is a technology that can be used to track changes to a project and to help multiple people to
collaborate on a project. At a basic level, a project version controlled by Git consists of a folder with
files in it, and Git tracks the changes that are made to the files in the project. This allows you to save
different versions of the work you're doing, which is why we call Git a version control system.
Git was created by Linus Torvalds to version control the work done on a large software development project
called the Linux kernel. However, since Git can track changes to all sorts of files, it can be used for a
wide variety of projects.